C Primer Plus读书笔记(一)
文章目录
本文是《C Primer Plus》第三章至第五章读书笔记。
ch03. 数据和C
思考问题:
- 各种类型的数据占用多少空间
- 各种类型的数据是如何格式化输出的
- 一般而言,存储int需要占用一个机器字长
- C语言中的byte不是8个bit,而是和一个char占用的位长一样
- char根据编译器不同,可能被处理成有符号也可能被处理成无符号。具体可以查看头文件limits.h
- 整数类型一般都被存储为int类型,当超过int最大范围,编译器会自动将其视为高一个等级的类型,直到越界
- 2^16 = 65536 / 2^8 = 256
- 浮点数的存储:有效数和指数部分(包括符号),3.16e^7,有效数部分就是3.16
- float至少能表示6位有效数字,double至少能表示10位有效数字
- 表达式中,float会自动转化成double
- 浮点数和整型数在计算机内部,虽然都是二进制表示,但是二进制的表示形式不一样,浮点数是把有效数字和指数部分分别表示。因此,在处理浮点数和整型的时候,计算机会做自动的转换,这个很危险
- 变量的初始化
- 定义变量时就会发配一块内存空间,如果没有对这块内存空间赋值(写入),那么读取出来的可能是残留在这个空间里的值,这个是很危险的
- 全局变量:初始化不给值的情况下,默认值为0
- 局部变量:如果不初始化给值,读出来的值不确定,这是危险行为
ch04. 字符串和格式化输入/输出
思考问题:
- 字符串是如何存取的
- 字符串底层的数据结构是怎样的
- 输入输出函数如何格式化
C语言中,没有专门的数据结构存放字符串。字符串是存放在char数组中,且数组的末尾是存放占位符'\0',这个占位符是自动添加到数组末尾
使用scanf读取字符串的时候,输入空格则停止读取
使用scanf读取字符串的时候,变量不需要通过&取地址(因为字符数组本身就是一个指针)
"x"和'x'的区别:前者是char数组,实际占用两个字符,后者是char类型,一个字符
sizeof - 字节长度 / strlen - 字符串长度
使用sizeof计算字符串,会把结束字符(空字符'\0')也算进去得到总共占用的字节数;而strlen计算字符串长度的时候,不会把末尾的结束字符计算进去
sizeof结果返回size_t类型,一个无符号整型
limits.h和float.h中分别定义了各种类型的最大值和最小值,这个会由于操作系统以及其字长的不同而不同
#define NAME value - 使用预处理器定义了一个明示常量,通常用大写来命名;const定义的实际是变量,可读变量
printf转换说明:把以二进制格式存储在计算机中的值转换成一系列字符串然后打印
转换如果和底层的数据类型不匹配会发生很奇怪的事情,如下代码:
- n1是float类型,但是在存储的时候会自动转换成double,因此占用8个字节,但是
%ld导致在转换说明的时候,只读取了前4个字节 - 以上,导致每一次
%ld的转换都发生错位,四次的%ld仅读取了16个字节,但是n1到n4一共占用了24个字节
1printf("%ld %ld %ld %ld\n", n1, n2, n3, n4);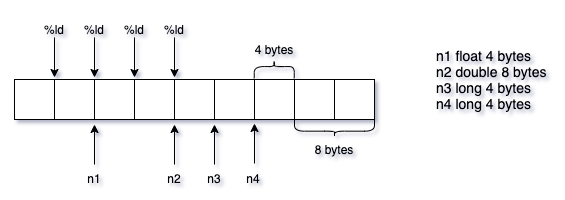
- n1是float类型,但是在存储的时候会自动转换成double,因此占用8个字节,但是
格式化字符串转换说明 (关于转换说明符修饰符P71)
转换说明 输出 %a %A 浮点数、十六进制数和p记数法 %c 单个字符 %d 有符号十进制整数 %e %E 浮点数,e %f 浮点数,十进制记数法 %g %G 根据值的不同,自动选择%f或%e。%e格式用于指数小于-4或者大于或等于精度时 %i 有符号十进制整数(与%d相同) %o 无符号八进制整数 %p 指针 %s 字符串 %u 无符号十进制整数 %x 无符号十六进制整数,使用十六进制数0f %X 无符号十六进制整数,使用十六进制数0F %% 打印一个百分号 %zd 打印size_t类型 scanf与printf正好相反,从键盘输入的都是字符串,scanf通过指定数据类型然后将字符串转换成对应的数据类型。注意:除了字符串类型及char数组,其他所有的类型都要通过指针来接收值
scanf通过空格或者回车将输入分割成多个字段(%c是例外,也会把空字符作为输入存储)
scanf的返回值是成功读取的项数(个数)
*修饰符
对于printf而言,*修饰符用于代替字段。如下面代码所示,*修饰符用与替换变量width
对于scanf而言,把*放在%和转换字符之间,则会跳过相应的输入项。下面代码所示,scanf跳过了第一个和第二个输入,把第三个输入赋值给n
1int main(void) { 2 unsigned width = 6, precision = 3; 3 int number = 256; 4 double weight = 242.5; 5 printf("%*d\n", width, number); // printf("%6d\n", width, number); 6 printf("%*.*f\n", width, precision, weight); 7 8 int n; 9 scanf("%*d %*d %d",&n); 10 printf("%d\n", n); 11 12 return 0; 13 14}
ch05. 运算符、表达符和语句
思考问题:
- C语言中有哪些运算符和表达符,运算符的优先级是怎么样的
- C语言中有哪些特殊的语句
- 自动类型转换和强制类型转换
赋值表达式的目的是把值存储到内存位置上
浮点数除法的结果是浮点数,整数除法的结果是整数(小数部分直接被截断,不会四舍五入 ),整数和浮点数的除法是浮点数
运算符优先级(从高到低)
运算符 结合律 - 运算符符合与运算对象结合 () 从左到右 + - (一元)++ -- sizeof ! 从右到左 * / % 从左到右 + - (二元) 从左到右 < > <= >= 从左到右 == != 从左到右 = 从右到左 上表结合律只适用于共享同一运算对象的运算符
- 6*3 + 4*5 - 可以肯定*优先级比+高,但是这例子中,6*3和4*5的运算先后顺序不确定,不同硬件平台可能顺序不一样(发生指令重排??)
- 12/3*2 - 这个例子中,/和*的优先级一样,但是3是共享运算对象,因此遵循结合律从左到右,所以先算12/3,然后4*2
求模运算只能用于整数,不能用于浮点数
a%b <=> a - (a/b)*b
自增和自减运算符 ++/--
- 前缀模式:先完成自增或者自减,然后再用结果参与同一语句中的其他运算
- 后缀模式:先完成同一语句的其他预算,然后再完成自增或者自减
- 如果只是单独使用,也就是不和其他运算对象以及运算符一起的时候,前缀和后缀模式都没有区别,就是要完成自增或者自减
下面两种情况不要使用自增后者自减(由于可能指令重排导致计算没有按预期的顺序进行)
- 一个变量出现在一个函数的多个参数中,那么不要对该变量使用自增或者自减
- 一个变量多次出现表达式中,那么不要对该变量使用自增或者自减 - ans = num/2 + 5*(1+num++),这里可能因为指令重排导致num++先算,那么前面的num/2就和预期不一样了
序列点:程序执行的点,在一个语句中,赋值运算符、自增自减运算符对运算对象做的改变必须在程序执行下一条语句之前完成
自动类型转换(通常应该要避免):
- 升级:较小类型转换成较大类型
- 降级:较大类型转换成较小类型 - 这种情况可能会发生数据截断
- 升级发生在表达式中运算对象数据类型不同,这时候发生自动自动类型转换。运算结束后,会根据目标类型可能会发生降级,这时候可能就会发生数据截断
强制类型转换:(type)variable
实参和形参
- 实参 argument - 调用函数时传递给形参的实际的值
- 形参 parameter - 函数签名上定义的变量
引用书中关于自动类型转换的一段:
在C语言中,许多类型转换都是自动进行的。当
char和short类型出现在表达式里或者作为函数的参数(函数原型除外)时,都会被升级为int类型;当float类型在函数参数中时,会被升级为double类型当把一种值赋给另一种类型的变量时,值将被转换成与变量的类型相同
当把较大类型转换成较小类型时,可能会丢失数据
- 函数声明 - 在调用函数的时候,编译器首先需要知道函数的返回类型,所以需要先声明函数,至于函数的实现可以放在后面